
Hi there!
Last week I got an opportunity to speak at PyConFr held at the Telecom Bretagne, engineering school and research center, in Rennes between October 13-16, 2016 and it was my first ever experience as a speaker at an international conference.
Fun fact: three things that people fear the most in this world are-
1. Death
2. Spiders
3. STAGE FRIGHT
So, naturally it was a daunting experience for me. I was probably the youngest there, I did not speak French, and I was surrounded by people who actually built this entire community of Python, which I was just entering. No pressure, there.
Honestly, I imagined myself to be completely alien to everything there, not knowing what to do, where to go, or whom to talk to. But the way things turned out over the next four days, was a 180 degree opposite of what I had thought and I am so glad it was that way.
The four day event kick-started with a two day sprint, where developers and contributors of various open source projects came together to code.
At the end of the two day sprint, we had an opening dinner-party-cuban-music-get-together for the conference. This was where all the attendees, speakers and the organizers gathered together for the first time, and it was so nice to meet them.
Specially the people I have known, but never met in person, like Alexis, who shared his experience as a tech speaker, having spoken at over 20 conferences before. Then there was Magopian, another Kinto member whom I hadn’t met before. He had some really useful tips and stories to share. I also met Nicole, who was working on the Warehouse project and coincidentally, she recalled spending 6 months in India as a part of the student exchange program. Naturally, we had a lot to talk about. I also met Sahil, Mathieu, Romain, and so many other friendly people who were extremely fun to talk to. I loved how welcoming the entire community was; people would actually go out of their way to make sure I felt at home!
The conference officially started the next morning with an opening ceremony by the organizers after which we had two jam-packed days of 5 parallel tracks, three for short/long talks and sessions and two for the workshops. And that’s when the real hustle began. People, hundreds of people, far more than expected, were rushing in the hallways to get to one of their favourite tracks. The fact that even the huge auditoriums were overflowing with people speaks volumes of what a great success the entire event was.
Even though most of the sessions were in French, I was glad to find that there were some talks in English as well. And the best part was that none of them overlapped, it was all impeccably managed.
The first talk I attended was by Bhargav Srinivasa Desikan, a GSoC intern who talked about performing effective topic modelling in Python using Gensium, an open source Python framework used for informational retrieval. He explained how we could effectively identify key topics in a large corpus of text documents which had heavy applications in both industry and the research sectors.
Then we had a talk by Sahil Dua, on the Python library, Pandas. He talked about data manipulation and indexing, with some really fun examples of statistics of number of goals scored by Ronaldo and Messi over the last 10 years. He explained various operations and functions which we could use and then implemented them over a live demo.
One really interesting session was conducted by Nicole Harris who talked about Warehouse, which is the next generation Python Package Repository, designed to replace the legacy code base that currently powers PyPI. She mentioned the achievements and the shortcomings of the project and discussed how they plan to move forward, inviting everyone to contribute to its success.

My talk on Web Push Notifications was scheduled on the last day. My relationship with this topic was from the Outreachy program, where my project was to enable real-time push notifications for Kinto. I talked about why web push notifications are important, what exactly are they, and how does the entire mechanism of push notification work, detailing the architecture and the technical building blocks that come into play.
There’s a great saying by Mark Twain that I love to share. He said, “there are two types of speaker: those that are nervous and those that are liars.”
And I do not lie. 🙂
So even though I was extremely nervous to be standing there in front of so many people, having some familiar, friendly faces in the crowd was all the support it took, for me to make it through. And honestly, I was just glad I could complete my talk without collapsing. 😛
All in all, it was a great experience being there, interacting with some of the nicest people, hearing about their experiences, getting to know them and learning so many new things!
A million thanks to the Python community for giving me this opportunity to be a part of the conference.
I wish to thank AFPy and the Outreachy program for supporting my travels and accommodation. Without their support, I could not have managed to avail this opportunity.
And lastly, to the one person without whom none of this would’ve been possible. My Mozilla mentor, Remy Hubscher, who was deliberately not mentioned in the entire article because words simply fail to describe what an incredible support he has been over the last six months.
Thank you!
Until next time. 🙂

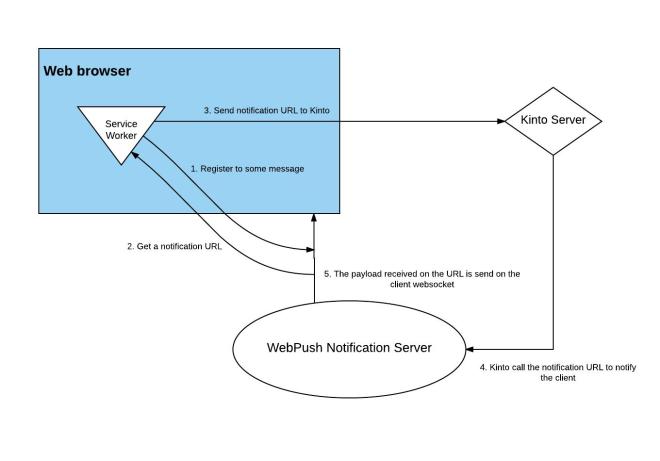 The entire process or workflow of Push Notification can be explained in a few simple steps:
The entire process or workflow of Push Notification can be explained in a few simple steps: